News
The latest buzz
The latest buzz

Dear readers and customers,
as the year draws to a close, we want to take a moment to pause, reflect, and celebrate with you. It has been a year of growth, creativity, and connection, and we’re grateful for you — our clients, partners and supporters — who made it all possible.
In the spirit of this special season, we wish you a Merry Christmas filled with warmth, joy, and small, bright moments. May you find laughter in the company of loved ones, comfort in familiar traditions, and countless new beautiful stories to treasure.
Looking ahead, may the New Year 2026 bring you inspiration, opportunity, and success in all your endeavors.
We’re excited to continue delivering high-quality, engaging content that informs, entertains, and fuels your passions. Thank you for being part of our publishing family. Contact us anytime via info@aethyx.eu.
Wishing you health, happiness, and many sunny days in the year that follows.
Warm regards,
your aethyx staff



Dear readers and customers,
we are happy to announce some successful updates for our running systems this month.
We tested it all and found no issues. But we would be very happy if you contact us if you witness something unusual while using our services: info@aethyx.eu.
Thank you for your patience and Happy Halloween!
Best wishes,
the aethyx staff

Dear readers and customers,
after all our Android development officially came to an end, we are now preparing the code one last time and will be uploading all what we have done into our GitLab repository here: https://gitlab.com/aethyx/opensource.
We will start with our e-zines zockerseele.com and gizmeo.com. And put the rest of our Android portfolio in our repository there by the end of the year.
This way, we want to give back what FOSS gave us all those years.
It was a wonderful time full of new experiences and a lot of headaches. Time flies too as we started this journey 2014 and we are in 2025 already.
We won’t, and simply can’t, provide any new code here. May it be a fresh start for something else we don’t even know of.
So long Android, and thanks for all the fish!
All the best,
the aethyx staff
Dear readers and customers,
it’s an issue of our time and can be observed from AI bots to politics: sycophancy.
But what is it and why is it here?
First of all, the complexity of our times are so exceptionally high we probably won’t be able to find a single root cause here. All we know is it’s here, it’s a problem which needs to be addressed and there’s not really much we can do individually. What’s important here is to develop a kind of awareness. As well as keeping it in mind on a daily basis, e.g. when talking to colleagues and friends, consuming media, etc.
In short, what it is:
“Sycophancy is insincere flattery given to gain advantage from a superior. A user of sycophancy is referred to as a sycophant or a “yes-man.” [via]
It may sound like a harmless negative character trait but unfortunately it isn’t. Keywords to take away here are “insincere”, “gain advantage from a superior” plus “yes-man”. We don’t live in times for “yes-men”, nothing outside currently is agreeable per se, it’s actually the other way round. The female component is missing here too. Furthermore, if someone or something is “insincere”, you can as well state it’s a joke. And neither AI topics nor politics are a joke or should be treated as such. This planet won’t exist 50-100 years from now on and there are polls which even state an exact date for Armaggeddon, which is in itself a remarkable statement of our times.
Whenever “dark patterns” arise, like seen with LLMs and AI models here, the process of eridacting a failure for the future failed. As such, we can’t turn back time and we wouldn’t advise even if the possibility existed. However, we can try to avoid it for the future. Be it for ourselves, AI bots, politics or whatever. The main problem here is people and individuals will be tricked and this is like gas lighting an entire society into oblivion. It will be a mind state and a world situation where human beings won’t be able to think about anything relevant anymore. If such a “dark pattern” already made it into a machine learning algorithm, we took the wrong turn somewhere in the past. With this post we want to sharpen our senses so that it might be the only dark pattern we found in AI bots five to ten years from now on.
Thank you for your help here and always keep in mind: we still hold it in our own hands. We can be the change, please spread this awareness and try to communicate it in a positive way. Humans are worth it. And always were.
Keep your head up and best wishes,
the aethyx staff
Dear readers and customers,
since a few weeks, we’re experimenting with different online ad forms:
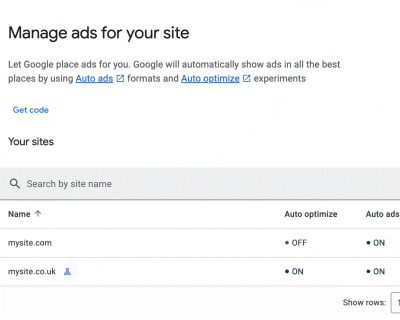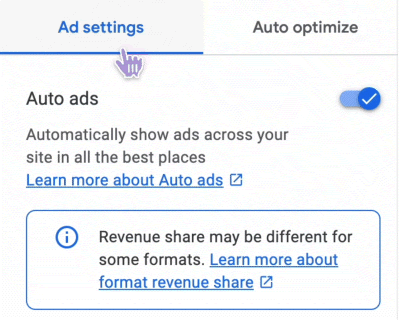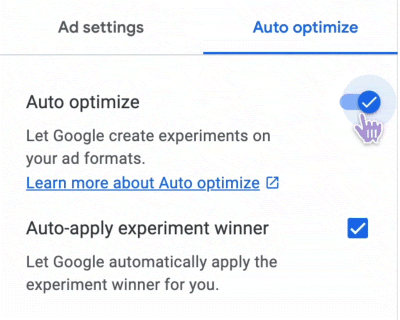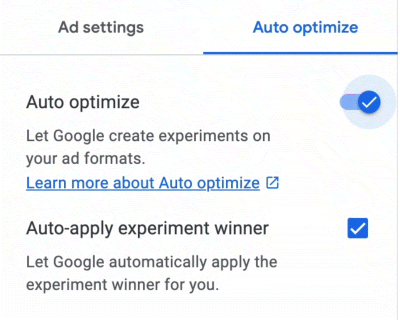
We do this with the help of our advertising provider Google on the following websites:
aethyx.eu, gizmeo.eu, jpcars.de, kryptogeld.io, kryptowiki.eu, yaaby.eu
Why we are doing this: as we mentioned earlier, generating revenue with independent projects is extremely hard. As such, any new idea we are offered will at least be taken into consideration. Like this one here.
How long will we be doing this: we will be using this new possibility of ad placement until the end of the year 2025. After this year, we compare our online ad revenue data from the first half of 2025 with the second one. If we didn’t generate more revenue, the idea will be scrapped and we will revert back to our old ad placement scheme. If it generates more income value for us, the setting will stay for the entire year of 2026. After the next year, a new evaluation will be produced and analysed. We will then proceed accordingly.
So don’t be surprised if you might see new ads here and there. We hope these stay relevant to the content and not too much of an inconvenience. To us, the idea looked promising. We now hope that it may change something to the better.
Thanks for supporting us and best wishes,
the aethyx staff